ISSCC(International Solid-State Circuits Conference,国际固态电路会议)是全球学术界和工业界公认的集成电路设计领域最高级别会议,被认为是“集成电路设计领域的奥林匹克大会”。继2021/2022年线上举办后,第70届ISSCC 于2023年2月19日至23日恢复线下举办。复旦大学芯片与系统前沿技术研究院、集成芯片与系统全国重点实验室刘明院士、刘琦教授团队提出了面向Transformer神经网络的存算一体芯片——天溪,以“A 28nm 53.8TOPS/W 8b Sparse Transformer Accelerator with In-Memory Butterfly Zero Skipper for Unstructured-Pruned NN and CIM-Based Local-Attention-Reusable Engine”为题的论文入选本年度ISSCC口头报告,并参加演示环节(Demo Session)。

图1 我院Transformer存算一体芯片在ISSCC 2023上口头报告
近来,Transformer神经网络在自然语言处理领域、计算机视觉和AI+Science领域等均得到了广泛的应用,特别是ChatGPT的出现进一步推动了大模型的对人们日常生活的影响。Transformer神经网络优越的性能来源于其特有的注意力机制和更大的网络规模,同时这些特点也对智能计算芯片提出了更高的要求。据统计,Transformer神经网络的计算量以每两年750倍的速度增长,参数量以每两年240倍的速度增长,显著超越了摩尔定律。对于Transformer大模型而言,存储和计算之间大规模的数据搬移产生了额外的延时和能耗,成为限制芯片性能的主要瓶颈。高能效的存算一体芯片可以大幅降低存储和计算的通信需求,但已有的工作主要集中于加速传统的卷积神经网络或循环神经网络,未考虑Transformer神经网络特有的注意力机制加速。此外,受限于计算阵列中各存算单元固定的互连关系,现有的存算一体芯片不能充分利用神经网络的非规则稀疏性。
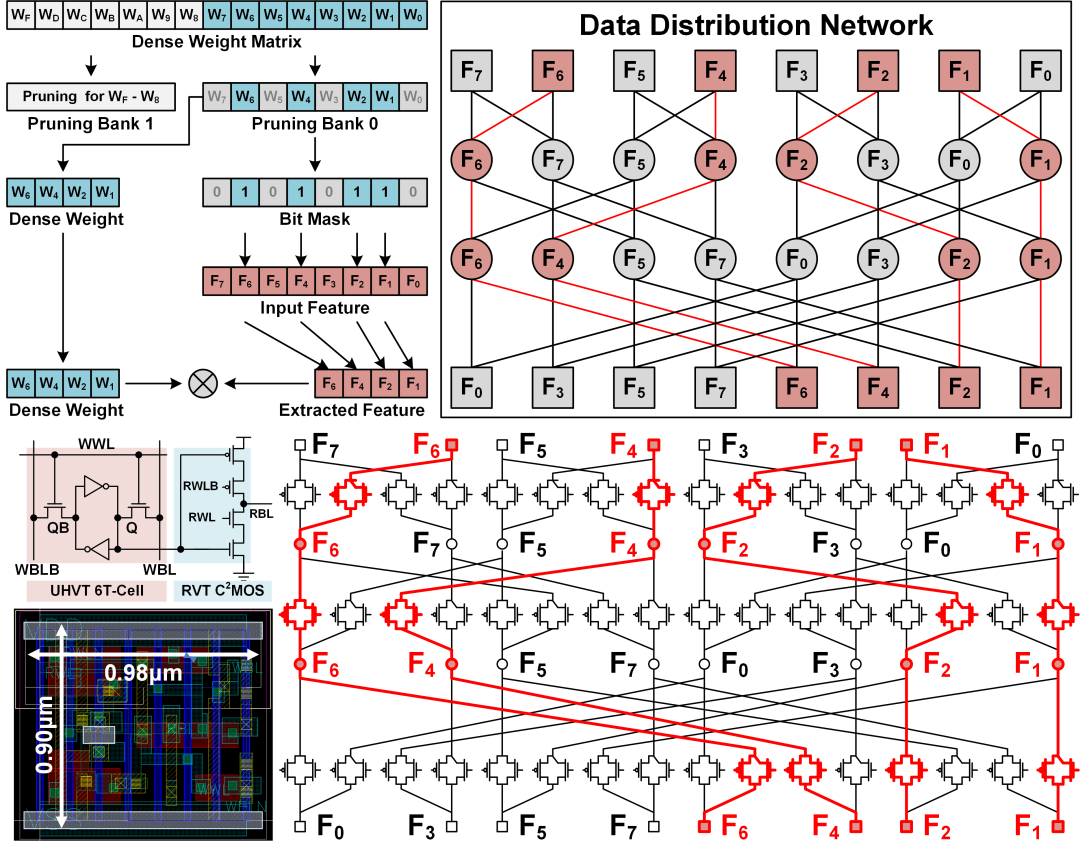
图2 基于基于蝶形网络的非规则稀疏性提取拓扑结构及其存内电路实现
为支持Transformer神经网络中的稀疏前馈网路,天溪存算一体芯片应用了基于蝶形数据分配网络的稀疏前馈计算架构(图2)。该架构将权重矩阵裁剪为局部细粒度、全局粗粒度的稀疏矩阵,并使用蝶形网络提取稀疏权重对应的特征值。在电路设计上,为进一步降低蝶形网络的功耗开销,天溪芯片采用了存算一体的设计思路,使用定制的存储单元和传输门逻辑在存算阵列中整合了数据分配通路(图2)。最后,为降低Transformer神经网络中注意力机制的计算和存储复杂度,天溪芯片采用了动态局部注意力机制和QK共享机制对原有注意力网络进行稀疏化,并对其计算和存储流程进行优化(图3)。天溪存算一体芯片使用28nm工艺流片,其峰值计算力达到了3.3TOPS。在分别计算前馈神经网络、注意力网络和Transformer神经网络时,系统能效分别达到了11.83TOPS/W,53.83TOPS/W和25.22TOPS/W,是已有面向Transformer神经网络加速器的3.2倍至9.7倍。
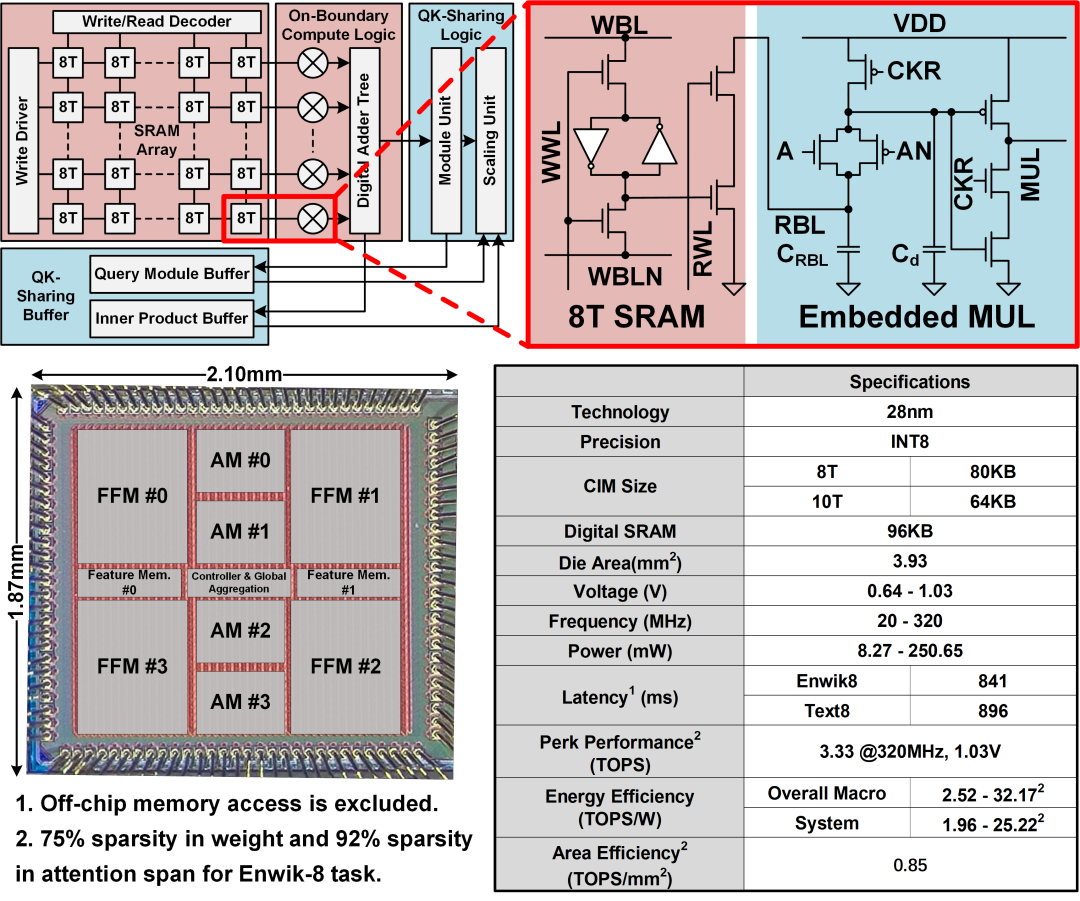
图3 稀疏注意力机制计算单元及芯片版图照片
该论文通讯作者为复旦大学芯片与系统前沿研究院的陈迟晓副研究员,博士生刘诗玮为第一作者,工程与应用技术研究院硕士生李沛哲、张锦山,芯片院/微电子学院博士后朱浩哲、硕士生王运正茂等对本工作也作了重要的贡献。
